Iris Flower Classifier

In this project, I attempted to implement a Random Forest Algorithm on The Iris Flower Dataset using a Scikit-learn package in Python. The Iris Flower dataset comes with the Scikit-Learn package itself, meaning that it is clean enough to be used for training an ML model. This is useful for the scope of this project as it will allow me to explore the Scikit-learn package and focus on the nature of the Random Forest Algorithm without spending time on obtaining, cleaning, and transforming data.
Objective
The objective of this project is to build a model that allows us to predict the type of an Iris flower based on its Petal and Sepal features such as length and width. By creating such a model we would be able to input whatever parameters we choose and determine the class to which our hypothetical Iris flower could belong.
The Data at Hand
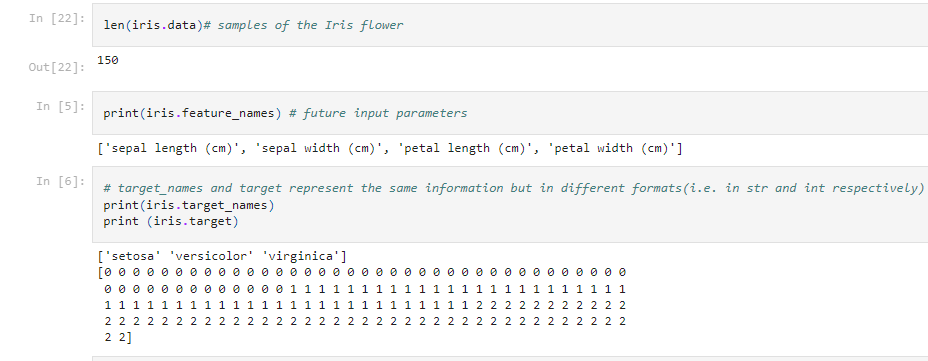
Upon the first look we can see:
- the "data" array which composites of a 150 flowers
- the "target" array that represents various class labels such as 0,1,2
- the "target_names" array which corresponds to the class labels above such as 'setosa', 'versicolor', 'virginica'
Additionally, the dataset contains a list of "feature_names" which represents the 4 characteristics of Iris Flower such as: "sepal Length"(cm),"sepal width"(cm); "petal length"(cm) and "petal width"(cm).
Iris Dataset gives us 1 class output variable (i.e."target"/"target_names") and 4 input features (i.e."feature_names"). This will inform the parameters used for out Classification Model.
Splitting and Training Data
I have chosen to split the dataset into a training set and a test set. This is done for the purpose of an unbiased evaluation of prediction performance. The Training set is applied to fit a model whilst a test set is used for an independent assessment of the final model. To do so I will use the model selection package of Scikit-learn, in particular on the function train_test_split():

The Test_Size value of 0.3 indicates to us the size of the test set. We can think of a 0.3 test size as 30%, with the remainder in this case (70%) indicating the training size.
Random Forest Algorithm
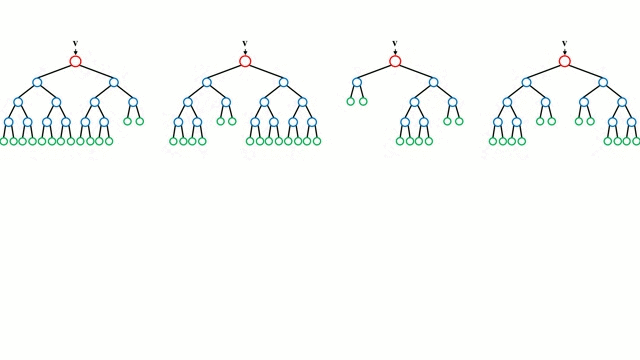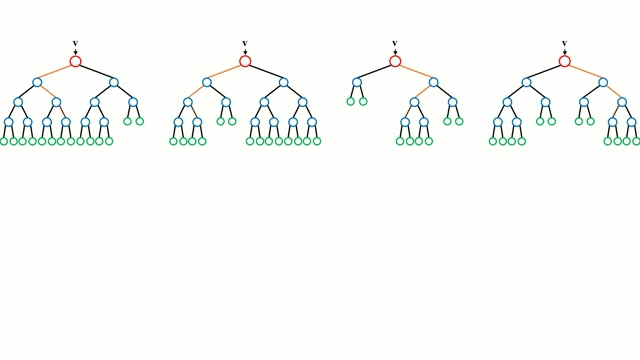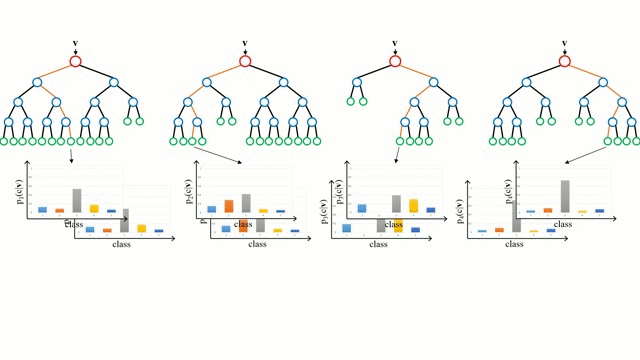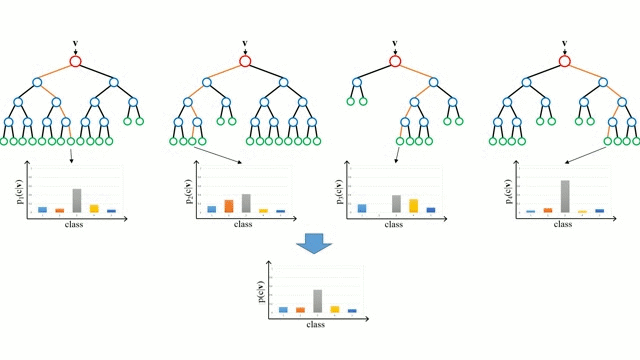
How exactly does a Random Forest Algorithm work? Random Forest algorithm is made up of many Decision Trees which operate together, thereby producing a strong "collective" guess. When used for Classification Models, all Decision Trees in the algorithm produce a class prediction with the most commonly chosen class becoming the prediction of the overall model.
Fundamentally, a Random Forest algorithm prediction is effective due to the low correlation between each class prediction produced by individual Decision Trees. In other words, each Decision Tree in a Random Forest algorithm makes up for the errors from other Trees. Although some class predictions of Decision Trees will be incorrect, a substantial number of predictions will be correct, moving the collective group of Trees in the right overall direction.
This process looks something like this:
Creating the Model
Having covered this, we can proceed with creating a Random Forest Classifier

The n_estimators above is the number of Decision Trees used for our model. The larger this number the slower (but also more accurate) is the model, in this case, we are using 100 Decision Trees for our Random Forest.
The Classification Model (clf) is trained using the X and y training sets created above:

Let us create a predicted value of y (i.e. y_pred) based on the input of X testing set (i.e.X-test) using a Random Forest Predict function:

As indicated above, our Random Forest generates the predicted value of y( i.e. classification of the Iris Flower) by using the predict function on the X input( i.e. the features of the Iris Flower).
Prediction
Using the code from above we can input a random array of X values of our choice and predict the classification of the Iris Flower at hand. We should bear in mind that the model is using the numerical representation of the Iris Flower Class. Thus the first prediction we obtain is the number of the class. Having found the predicted numeric value of the class to which our hypothetical Iris flower belongs, we can match it to the appropriate Class name:

And the Output is:

Evaluating Accuracy
To assess and calculate the accuracy of our model we will have to import metrics package from Scikit-learn. Then we must use a metrics accuracy_score function of y testing set( i.e. y_test) against the predicted y value of our model( i.e. y_pred):

What the metrics accuracy_score function shows the percentage of correct predictions. This also could be simply found by a few lines of code I wrote below:

The metrics accuracy function as well as my own calculations conclude that the accuracy of the Iris classification model is over 90%. We should note that the accuracy of the model will vary every time you run the code because of the nature of the Random Forest algorithm. For that reason, it is important to double-check the metrics.accuracy_score function from Scikit-Learn with your own calculations as I have done above.
Significant Parameters
Having evaluated the accuracy of the model we may be interested in considering which input parameters of the model play the most significant role in determining our predictions. Below is the chart that demonstrates my findings:
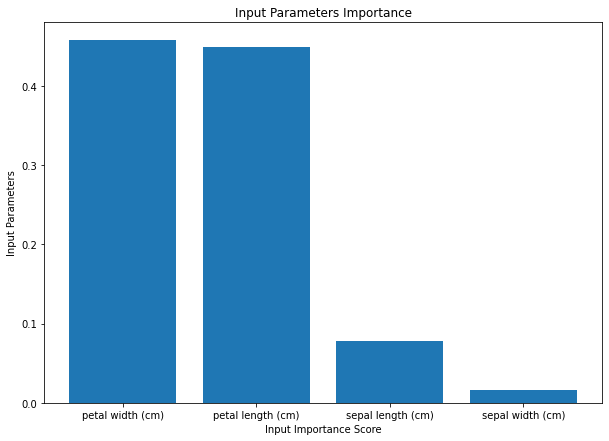
Conclusion:
In this project, we have managed to build a classification model for the Iris Flower Dataset using the Random Forrest Algorithm by focusing on the Petal and Sepal features of the Iris Flower.
The input parameters of the petal play a significant role in determining the classification prediction whilst the parameter of sepal width seems to be of little importance. According to the accuracy function and my own calculations, the model produces an accurate prediction over 90% of the time.
Follow the link below to view my code in greater detail.
Github Link

