Credit Card K-Means Clustering

In this project, I attempted to make sense of Credit Card customer data I came across on Kaggle. The dataset contained information about approximately 9000 active credit card users over a 6 months period.
Objective:
In order to better understand the data at hand, I decided to implement a K-Means Clustering algorithm from the Scikit-Learn package in Python. The objective behind using this algorithm was to create clusters of customers based on the balance to credit limit ratio in their accounts. The clusters would serve to better inform the bank's management of customer touchpoints such as a potential email marketing campaign.
Below is the plot of the data we will be working with prior to the creation of customer clusters:
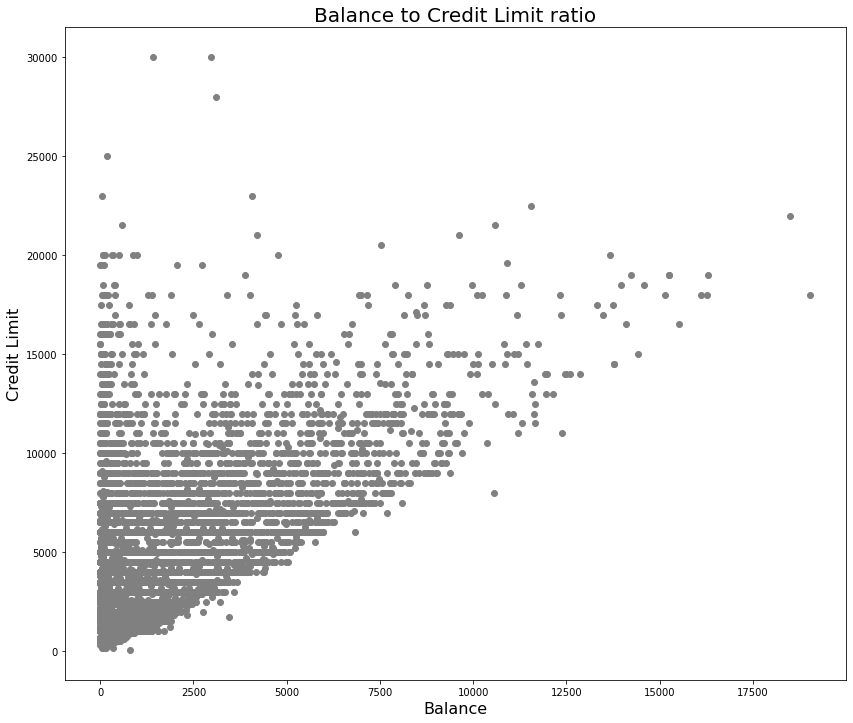
Note:
It is important to highlight that the dataset we are working with is not perfect for the application of the K-Means Clustering Algorithm.
Oftentimes data we work with can be quite noisy( i.e. containing duplicates, outliers, or simply being incomplete). This can be a big problem for a project like this for improper data can affect the results we get from ML operations, leading to erroneous answers and, consequently, erroneous suggestions.
There are certain things we need to be on the lookout for when performing K-Means Clustering:
- The values we are working with must be numerical
- Secondly, our data must not contain any outliers or missing/duplicate values that create noise (the K-Means algorithm is notoriously sensitive to them)
- Lastly, our data must be on the same scale having the same mean and variance
Thus I begin by ensuring that our dataset meets the parameters listed above.
What is a K-Means Clustering Algorithm?
Before applying the K-Means Clustering algorithm to our dataset let us first understand how it works and what it is supposed to achieve.
In simple terms, K-Means is a method that aims to partition our observations into a set amount of clusters in which each of our observations belongs to the cluster with the nearest cluster center (i.e. cluster centroid). Upon the first iteration, these clusters will be set at random. On the second iteration, we adjust the location of centroids by finding the mean of every cluster. This process is repeated until the variance is minimised and the centroids are no longer moving. The algorithm then chooses the centroids with the lowest total variance.
The visual representation of this process is shown below:
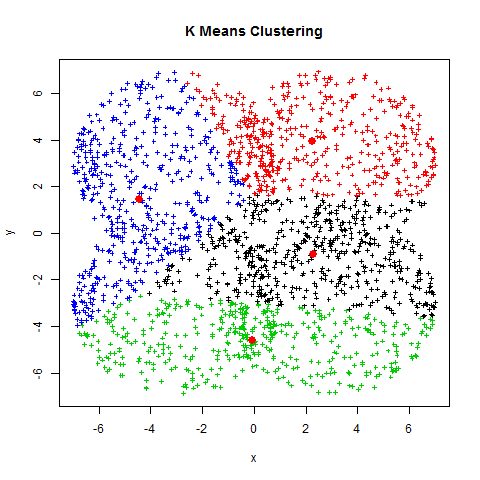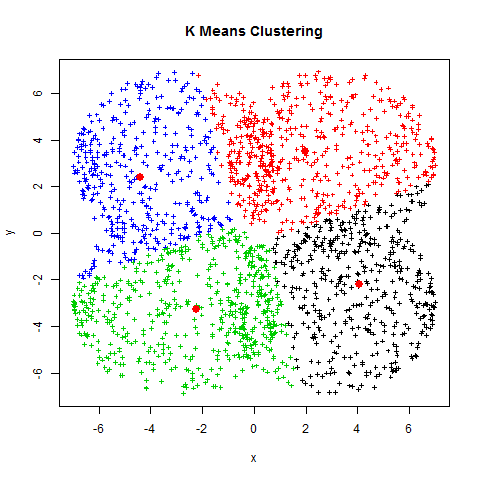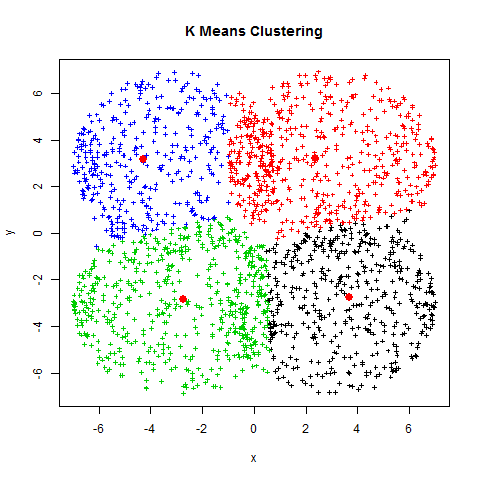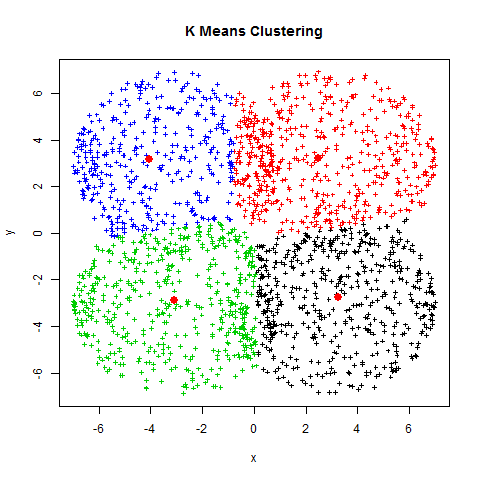
The Problem - Finding optimal K value
The problem we are faced with when creating customer clusters on a messy dataset is that we have no clue about how many clusters we need to create?
Theoretically speaking, if we would have an equal number of clusters to the number of observations, the distance between data points to the cluster centroids would be minimal. Nonetheless, in this case, we would not have any meaningful clusters and our problem would be unresolved. For that reason, we can utilize the Elbow Method to find the optimal number of clusters (i.e. K).
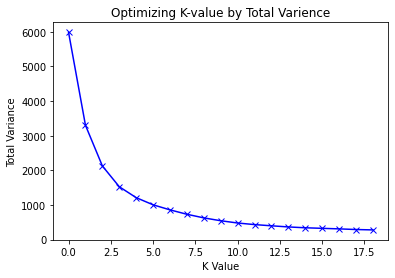
From the Elbow Method graph above we can see that with each run the total variance is minimised until it hits a plateau. Our optimal K value lies at the point where total variance is minimal but does not reach zero (which is the elbow of the curve). In this example, the elbow of the curve is approximately between 7 and 7.5.
For my K-Means Clustering algorithm, I choose a K value of 7.
Application of the Algorithm
Having used Python's Scikit-Learn Package I managed to create 7 Clusters of Customers based on the state of their account's Credit Limit and Credit Balance.
Here are my results:
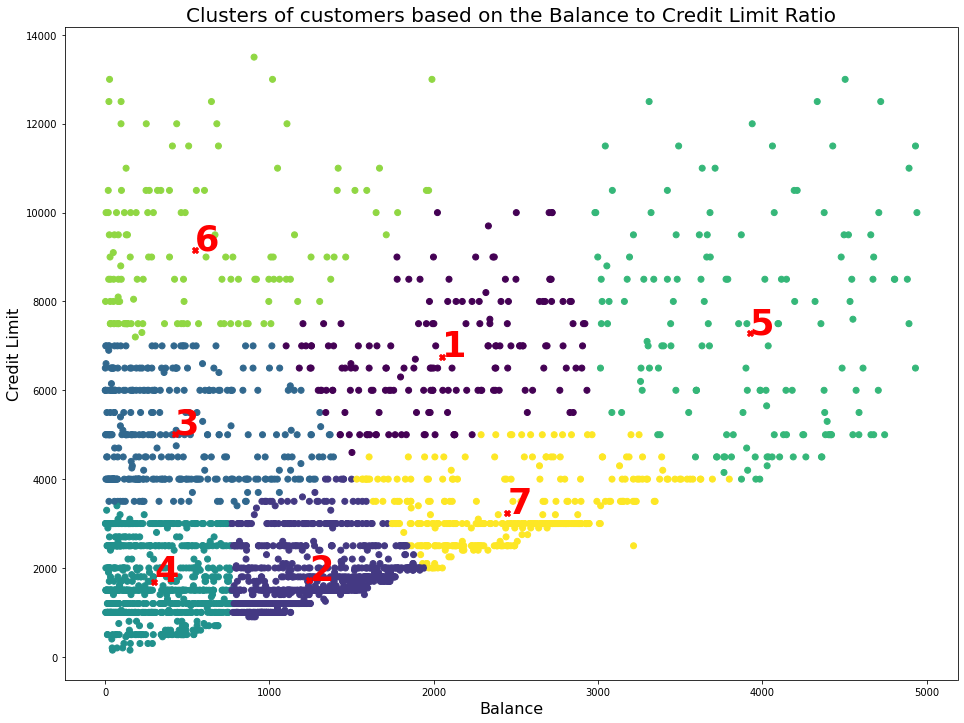
Application
We can use our customer segmentation above to inform an email marketing campaign. Below are the suggestions for the type of outreach each cluster of customers should receive:
- For clusters 1 and 5 Run a check if they are qualified for a higher credit limit. Bring to their attention that a higher credit limit can lower credit utilization, potentially boosting credit score and providing an additional emergency fund safety net. Customers in Cluster 1 that lean towards the higher balance may be cautioned that if an increased credit limit encourages spending outside of their budget, the benefits of having a higher limit could be outweighed by unmanaged debt.
- For cluster 2 send help to newer customers to encourage the usage of their credit cards(assuming that they are new give the lowest balance and credit scores from the overall group). Perhaps suggest an appointment where they can receive advice on how to use their credit cards more effectively.
- For Clusters 3 and 6 the credit limit to credit balance ratio is high. These customers would have a high credit score and thus you could suggest some additional rewards to nurture the relationship with these customers. Customers in cluster 3 in particular can qualify for higher rewards.
- Customers in cluster 7 are well within their credit limit and their balance does not exceed it. These customers have the potential to move into clusters 3 and 6 which is the desired area for the business.
- The customers in the remaining cluster 4 have relatively high balances compared to their credit limits with some of them even exceeding their limit. These customers should be encouraged to work on ways of improving their credit scores and paying off their balance.
Follow the link below to view my code in greater detail.
Github Link

